
Recently, We upgraded our Sitecore Managed Cloud environments to AKS 1.31 and right after that, our application deployment pipeline started failing. Everything had been working perfectly before the upgrade, and the exact same pipeline was still passing on environments that hadn’t been upgraded yet.
One of the custom role jobs started failing
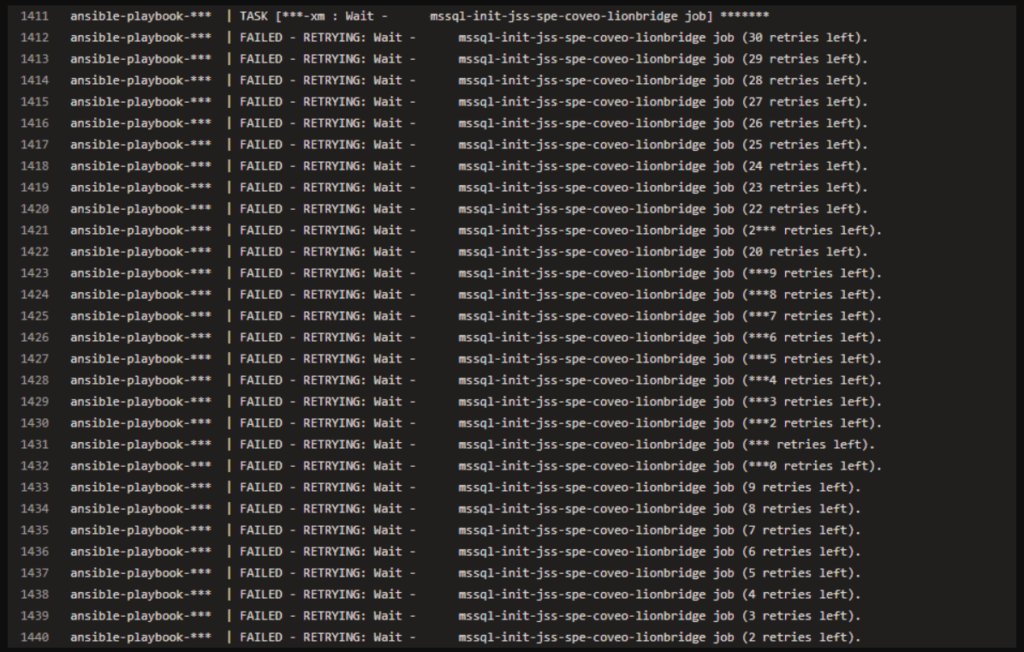
Custom Job That Wouldn’t Complete
The failing step was the Ansible task that waits for our MSSQL init job to finish. Here’s what it looked like:
- name: 'Wait - mssql-init-jss-spe-coveo-lionbridge job'
k8s_info:
kind: Job
name: mssql-init-jss-spe-coveo-lionbridge
namespace: "{{ solution_id }}"
register: avid_mssql_init_result
until: (mssql_init_result.resources[0].status.conditions[0].type | default('')) == 'Complete'
retries: 30
delay: 60
This task had been running fine for years but after the upgrade, it suddenly stopped working. The pipeline would just hang, waiting forever.
Error That Started Showing Up
I also started seeing this error in the job logs:
reason: FailedToRetrieveImagePullSecret
message: >-
Unable to retrieve some image pull secrets (sitecore-docker-registry);
attempting to pull the image may not succeed.
source:
component: kubelet
host: akspv21000000
This wasn’t the main issue, but it was a clue that something about how the cluster handled jobs and permissions had changed.
Finding the Root Cause
With help from the Sitecore support team we dug into the job’s YAML definition:
kubectl get job mssql-init-jss-spe-coveo-lionbridge -n sitecore -o yaml
That’s when we noticed something new in Kubernetes 1.31.
Before the upgrade, the job’s .status.conditions list had only one entry, like this:
- type: Complete
status: True
After the upgrade, it now looked like this:
- type: SuccessCriteriaMet
status: True
- type: Complete
status: True
The Ansible script was checking the first condition ([0]), expecting it to be "Complete".
But now the first condition was "SuccessCriteriaMet", so the task never recognized that the job had finished.
The Fix
The quickest fix was to change the index from [0] to [1] in the condition check:
until: (avid_mssql_init_result.resources[0].status.conditions[1].type | default('')) == 'Complete'
A more future-proof way is to check for the condition type by name, instead of relying on its position:
until: >
('Complete' in
[c.type for c in avid_mssql_init_result.resources[0].status.conditions])
Or even simpler, you can check if the job succeeded:
until: (avid_mssql_init_result.resources[0].status.succeeded | default(0)) == 1
Summary
- Kubernetes 1.31 changed job condition order, which broke some existing automation logic.
- Never rely on fixed array positions like
[0]for conditions always check by name or use.status.succeeded. - Recheck image pull secrets after upgrades; permissions or bindings can sometimes reset.
A big shout out and thank you to Sitecore support team for helping figure out the root cause.